Data Engineering Framework
A Disciplined Approach to Supervising and Assessing Data Platforms
Introduction
In today’s data-driven world, robust data engineering is critical for organizational success, enabling seamless data flows, scalability, and reliability. The Data Engineering Framework offers a disciplined methodology for supervising and assessing data platforms, ensuring they meet technical, operational, and ethical standards. Built on our core Four-Stage Platform—Acquire and Process, Visualize, Interact, and Retrieve—this framework empowers organizations to build and maintain data ecosystems that drive innovation and efficiency.
Designed for entities of all sizes—from startups to global enterprises—the framework integrates principles from systems engineering, DevOps, and data governance standards like DAMA-DMBOK and ISO 27001. By addressing platform reliability, performance scalability, ethical compliance, and technological adaptability, it ensures data platforms align with organizational goals while fostering stakeholder trust and operational resilience.
Whether a small business streamlining local data flows, a medium-sized firm scaling infrastructure, a large corporate managing global pipelines, or a public entity ensuring data accountability, this framework delivers a pathway to data engineering excellence.
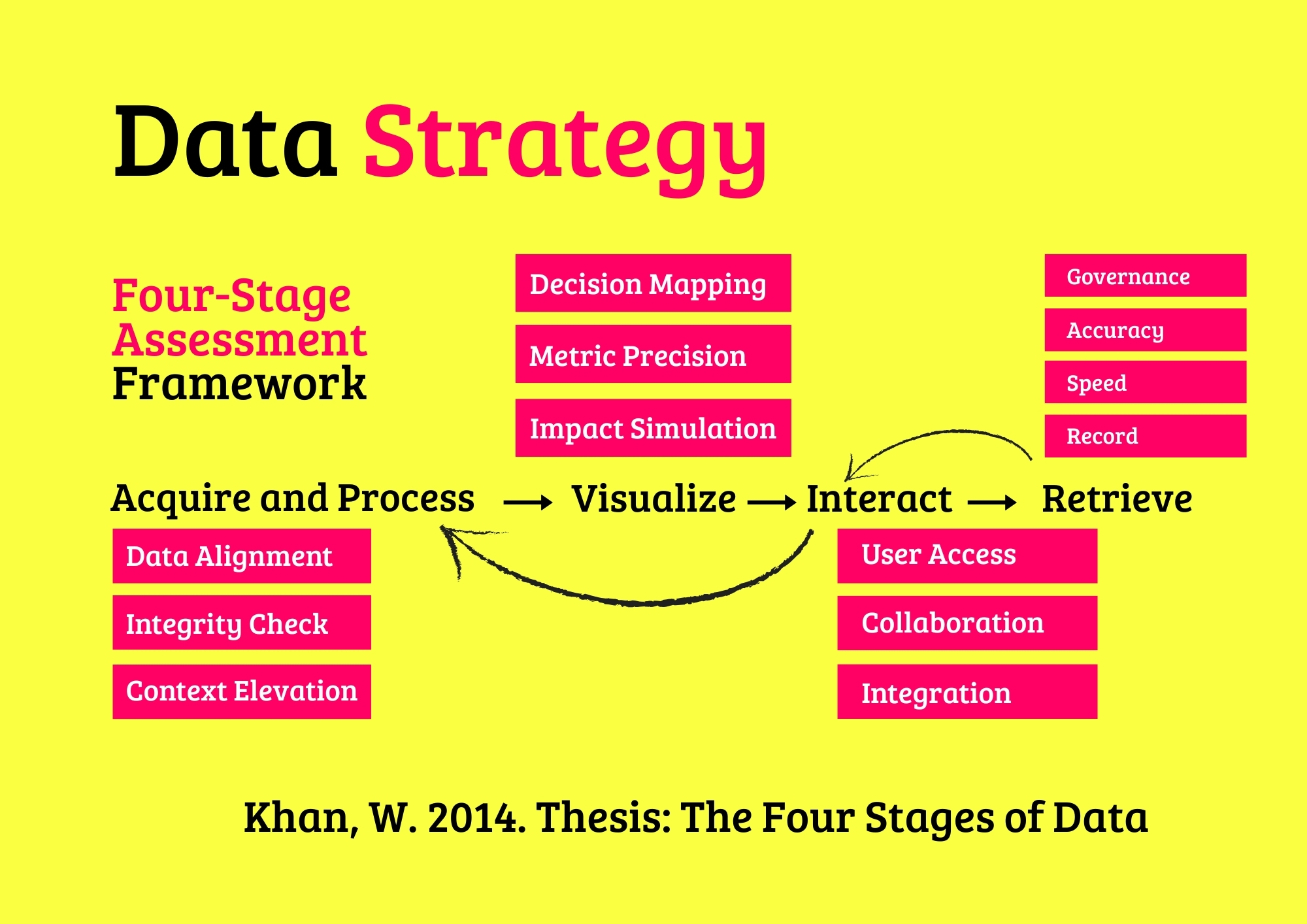
Theoretical Context: The Four-Stage Platform
Structuring Data Engineering for Supervision and Assessment
The Four-Stage Platform—(i) Acquire and Process, (ii) Visualize, (iii) Interact, and (iv) Retrieve—provides a structured lens for managing data platforms. Drawing from systems architecture and continuous integration principles, this framework emphasizes proactive supervision and iterative assessment to maintain platform integrity. Each stage is evaluated through sub-layers addressing technical performance, operational efficiency, ethical governance, and innovation.
The framework supports approximately 40 engineering practices across categories—Data Ingestion, Monitoring and Insights, Pipeline Interaction, and Storage and Retrieval—ensuring comprehensive oversight. This structured approach enables organizations to navigate data complexities, delivering platforms that are robust, adaptable, and aligned with sustainability goals.

Core Engineering Practices
Engineering practices are categorized by their objectives, enabling precise platform supervision. The four categories—Data Ingestion, Monitoring and Insights, Pipeline Interaction, and Storage and Retrieval—encompass 40 practices, each tailored to specific platform needs. Below, the categories and practices are outlined, supported by applications from systems engineering and DevOps.
1. Data Ingestion
Data Ingestion practices ensure reliable data acquisition and processing, grounded in automation for scalability.
- 1. Source Integration: Connects diverse inputs (e.g., APIs).
- 2. Schema Validation: Enforces structure (e.g., Avro).
- 3. Batch Ingestion: Handles bulk data (e.g., Apache Spark).
- 4. Stream Processing: Enables real-time (e.g., Apache Kafka).
- 5. Data Cleansing: Removes errors (e.g., Pandas).
- 6. ETL/ELT Pipelines: Transforms data (e.g., dbt).
- 7. Fault Tolerance: Mitigates failures (e.g., retries).
- 8. Metadata Capture: Tracks lineage (e.g., OpenLineage).
- 9. Cloud Ingestion: Leverages AWS/GCP (e.g., Kinesis).
- 10. Data Partitioning: Optimizes storage (e.g., sharding).
2. Monitoring and Insights
Monitoring and Insights practices provide visibility into platform performance, leveraging analytics for proactive management.
- 11. Pipeline Monitoring: Tracks flows (e.g., Grafana).
- 12. Data Quality Checks: Ensures accuracy (e.g., Great Expectations).
- 13. Latency Tracking: Measures delays (e.g., Prometheus).
- 14. Error Logging: Records issues (e.g., ELK Stack).
- 15. Anomaly Detection: Spots irregularities (e.g., ML models).
- 16. Dashboard Creation: Visualizes metrics (e.g., Tableau).
- 17. Alert Systems: Notifies issues (e.g., PagerDuty).
- 18. Compliance Audits: Verifies standards (e.g., SOC 2).
- 19. Resource Usage: Monitors costs (e.g., CloudWatch).
- 20. Performance Reports: Summarizes trends.
3. Pipeline Interaction
Pipeline Interaction practices enable dynamic management and optimization, rooted in orchestration for efficiency.
- 21. Workflow Orchestration: Schedules tasks (e.g., Apache Airflow).
- 22. Version Control: Tracks changes (e.g., GitOps).
- 23. Dependency Mapping: Manages flows (e.g., Dagster).
- 24. Query Optimization: Speeds access (e.g., indexing).
- 25. Caching: Reduces latency (e.g., Redis).
- 26. Scalability Testing: Validates capacity.
- 27. Load Balancing: Distributes traffic (e.g., Kubernetes).
- 28. Automated Scaling: Adjusts resources (e.g., auto-scaling).
- 29. API Management: Enables access (e.g., GraphQL).
- 30. User Access Control: Restricts permissions (e.g., IAM).
4. Storage and Retrieval
Storage and Retrieval practices ensure secure and efficient data access, grounded in governance for compliance.
- 31. Data Warehousing: Centralizes storage (e.g., Snowflake).
- 32. Data Lakes: Stores raw data (e.g., Delta Lake).
- 33. Encryption: Secures data (e.g., AES-256).
- 34. Backup Systems: Ensures recovery (e.g., snapshots).
- 35. Access Auditing: Tracks usage (e.g., CloudTrail).
- 36. Data Compression: Saves space (e.g., Parquet).
- 37. Indexing: Speeds retrieval (e.g., Elasticsearch).
- 38. Anonymization: Protects privacy (e.g., masking).
- 39. Retention Policies: Manages lifecycle (e.g., GDPR).
- 40. Disaster Recovery: Restores systems (e.g., DR plans).
The Data Engineering Framework
The framework leverages the Four-Stage Platform to assess data engineering strategies through four dimensions—Acquire and Process, Visualize, Interact, and Retrieve—ensuring alignment with technical, operational, and ethical imperatives.
(I). Acquire and Process
Acquire and Process establishes robust data pipelines. Sub-layers include:
(I.1) Data Ingestion
- (I.1.1.) - Connectivity: Integrates sources (e.g., APIs).
- (I.1.2.) - Validation: Ensures data quality.
- (I.1.3.) - Scalability: Handles volume spikes.
- (I.1.4.) - Innovation: Uses serverless ingestion.
- (I.1.5.) - Ethics: Prevents biased data inputs.
(I.2) Data Transformation
- (I.2.1.) - Accuracy: Ensures reliable processing.
- (I.2.2.) - Automation: Streamlines ETL/ELT.
- (I.2.3.) - Traceability: Tracks lineage.
- (I.2.4.) - Innovation: Leverages dbt.
- (I.2.5.) - Sustainability: Minimizes compute costs.
(I.3) Pipeline Resilience
- (I.3.1.) - Fault Tolerance: Mitigates failures.
- (I.3.2.) - Efficiency: Optimizes throughput.
- (I.3.3.) - Compliance: Aligns with regulations.
- (I.3.4.) - Innovation: Uses retry mechanisms.
- (I.3.5.) - Inclusivity: Supports diverse formats.
(II). Visualize
Visualize provides insights into platform health, with sub-layers:
(II.1) Performance Monitoring
- (II.1.1.) - Accuracy: Tracks data flows.
- (II.1.2.) - Timeliness: Detects issues fast.
- (II.1.3.) - Coverage: Monitors all pipelines.
- (II.1.4.) - Innovation: Uses AI-driven alerts.
- (II.1.5.) - Sustainability: Tracks resource use.
(II.2) Data Quality Insights
- (II.2.1.) - Precision: Identifies errors.
- (II.2.2.) - Automation: Reduces manual checks.
- (II.2.3.) - Trust: Ensures reliable outputs.
- (II.2.4.) - Ethics: Flags biased data.
- (II.2.5.) - Scalability: Handles large logs.
(II.3) Compliance Tracking
- (II.3.1.) - Adherence: Meets GDPR/ISO 27001.
- (II.3.2.) - Transparency: Logs actions.
- (II.3.3.) - Accountability: Assigns ownership.
- (II.3.4.) - Innovation: Uses blockchain logs.
- (II.3.5.) - Inclusivity: Ensures fair reporting.
(III). Interact
Interact enables dynamic pipeline management, with sub-layers:
(III.1) Workflow Orchestration
- (III.1.1.) - Efficiency: Streamlines schedules.
- (III.1.2.) - Accuracy: Prevents errors.
- (III.1.3.) - Scalability: Handles complexity.
- (III.1.4.) - Innovation: Uses Airflow.
- (III.1.5.) - Ethics: Ensures fair automation.
(III.2) Resource Optimization
- (III.2.1.) - Speed: Reduces latency.
- (III.2.2.) - Cost: Minimizes spend.
- (III.2.3.) - Reliability: Prevents bottlenecks.
- (III.2.4.) - Innovation: Leverages caching.
- (III.2.5.) - Sustainability: Optimizes compute.
(III.3) User Access
- (III.3.1.) - Security: Restricts permissions.
- (III.3.2.) - Usability: Simplifies interaction.
- (III.3.3.) - Compliance: Logs access.
- (III.3.4.) - Innovation: Uses single sign-on.
- (III.3.5.) - Inclusivity: Supports diverse users.
(IV). Retrieve
Retrieve ensures secure and efficient data access, with sub-layers:
(IV.1) Data Storage
- (IV.1.1.) - Scalability: Supports growth.
- (IV.1.2.) - Security: Encrypts data.
- (IV.1.3.) - Compliance: Meets ISO 27001.
- (IV.1.4.) - Innovation: Uses data lakes.
- (IV.1.5.) - Ethics: Protects privacy.
(IV.2) Data Retrieval
- (IV.2.1.) - Speed: Accelerates queries.
- (IV.2.2.) - Accuracy: Ensures correct data.
- (IV.2.3.) - Reliability: Prevents failures.
- (IV.2.4.) - Innovation: Uses indexing.
- (IV.2.5.) - Sustainability: Minimizes costs.
(IV.3) Governance
- (IV.3.1.) - Auditing: Tracks usage.
- (IV.3.2.) - Retention: Manages lifecycle.
- (IV.3.3.) - Accountability: Assigns ownership.
- (IV.3.4.) - Innovation: Uses automated policies.
- (IV.3.5.) - Ethics: Ensures transparency.
Methodology
The assessment is rooted in systems engineering and DevOps, integrating governance and ethical principles. The methodology includes:
-
Platform Audit
Collect data via logs, interviews, and pipeline reviews. -
Health Evaluation
Assess reliability, efficiency, and compliance. -
Gap Analysis
Identify weaknesses, such as slow ingestion. -
Roadmap Development
Propose solutions, from orchestration to encryption. -
Continuous Supervision
Monitor and refine iteratively.
Data Engineering Value Example
The framework delivers tailored outcomes:
- Startups: Build lean pipelines with real-time ingestion.
- Medium Firms: Scale platforms with automated monitoring.
- Large Corporates: Secure global pipelines with encrypted retrieval.
- Public Entities: Ensure trust with audited data access.
Scenarios in Real-World Contexts
Small E-Commerce Firm
A retailer faces slow data ingestion. The assessment reveals weak streaming (Acquire and Process: Data Ingestion). Action: Deploy Kafka. Outcome: Processing time cut by 20%.
Medium Logistics Company
A firm struggles with visibility. The assessment identifies poor monitoring (Visualize: Performance Monitoring). Action: Implement Grafana. Outcome: Issue detection rises by 15%.
Large Financial Institution
A bank needs efficient pipelines. The assessment notes complex workflows (Interact: Workflow Orchestration). Action: Adopt Airflow. Outcome: Pipeline efficiency up 10%.
Public Agency
An agency seeks secure access. The assessment flags weak encryption (Retrieve: Data Storage). Action: Use AES-256. Outcome: Compliance achieved, trust up 25%.
Get Started with Your Data Engineering Assessment
The framework aligns platforms with goals, ensuring scalability and security. Key steps include:
Consultation
Discuss platform needs.
Assessment
Evaluate pipelines comprehensively.
Reporting
Receive gap analysis and roadmap.
Implementation
Execute with continuous supervision.
Contact: Email hello@caspia.co.uk or call +44 784 676 8083 to enhance your data platforms.
We're Here to Help!

Inbox Data Insights (IDI)
Turn email chaos into intelligence. Analyze, visualize, and secure massive volumes of inbox data with Inbox Data Insights (IDI) by Caspia.

Data Security
Safeguard your data with our four-stage supervision and assessment framework, ensuring robust, compliant, and ethical security practices for resilient organizational trust and protection.

Data and Machine Learning
Harness the power of data and machine learning with our four-stage supervision and assessment framework, delivering precise, ethical, and scalable AI solutions for transformative organizational impact.

AI Data Workshops
Empower your team with hands-on AI data skills through our four-stage workshop framework, ensuring practical, scalable, and ethical AI solutions for organizational success.
Data Engineering
Architect and optimize robust data platforms with our four-stage supervision and assessment framework, ensuring scalable, secure, and efficient data ecosystems for organizational success.
Data Visualization
Harness the power of visualization charts to transform complex datasets into actionable insights, enabling evidence-based decision-making across diverse organizational contexts.

Insights and Analytics
Transform complex data into actionable insights with advanced analytics, fostering evidence-based strategies for sustainable organizational success.
Data Strategy
Elevate your organization’s potential with our AI-enhanced data advisory services, delivering tailored strategies for sustainable success.
AI Business Agents in Action
Inbound AI Agent for Real-Time Enquiries
Caspia’s Inbound AI Agent now handles over 80 percent of first-contact enquiries, routing calls, chats, and emails instantly to the right departments and reducing response time to under 10 seconds.

Lena
Statistician
Outbound AI Agent for Proactive Engagement
The Outbound AI Agent connects with customers automatically through personalised calls and data-driven follow-ups, increasing conversion rates by 25 percent across multiple industries.

Eleane
AI Researcher
Predictive Analytics Behind Every Interaction
Each AI Business Agent uses predictive models that analyse behavioural data in real time, adapting tone, timing, and messaging for the highest impact.

Edmond
Mathematician
Web and Chat AI Agent for Customer Journeys
Deployed across websites and WhatsApp, Caspia’s Web and Chat AI Agent provides a seamless experience, answering questions, taking bookings, and completing secure payments 24 hours a day.

Sophia
Data Scientist
Voice and Telephony Integration
With native telephony integration, AI Agents can call clients directly, provide spoken updates, or schedule voice-based confirmations, linking natural language with data-driven logic.

Kam
Programmer
Connecting Business Data to Human Conversations
Every conversation handled by the AI Business Agent connects to live business data, allowing instant retrieval of order details, account balances, and workflow status without human intervention.

Jasmine
Data Analyst
Learning from Every Call
Each interaction trains the AI Business Agent further. Feedback loops allow it to identify recurring issues and propose workflow improvements automatically.

Jamie
AI Engineer
Reducing Operational Load
AI Business Agents now process up to 65 percent of transactional workloads that once required staff support, freeing human teams to focus on creative and strategic tasks.

Julia
Statistician
Seamless API and CRM Integration
Inbound and Outbound Agents connect directly to CRM and ERP systems through secure APIs, ensuring every call, chat, and transaction syncs instantly with enterprise records.

Felix
Data Engineer
Context-Aware Understanding
Unlike traditional bots, Caspia’s AI Agents interpret context, intent, and emotional tone, providing responses that align with both brand language and customer sentiment.

Mia
AI Researcher
Data-Driven Decision Layer
The AI Agent network connects analytics with action, drawing from company dashboards and data stores to decide and execute responses intelligently in real time.

Paul
Mathematician
Multilingual Communication
The Web and Chat AI Agent converses in over 25 languages and dialects, giving multinational clients a consistent and localised engagement channel.

Emilia
Data Scientist
Automating Repetitive Workflows
Outbound AI Agents handle reminders, renewals, and confirmations automatically. Businesses save hundreds of staff hours every quarter by automating these interactions.

Danny
Programmer
Transforming Data into Dialogue
With AI Business Agents, data isn’t just visualised, it’s spoken. The system can narrate insights from Power BI, Tableau, and Looker dashboards directly during meetings.

Charlotte
Data Analyst
Continuous Learning through Interaction
Every question, correction, and response becomes part of a continuous learning model that improves the AI Agent’s understanding and accuracy across all channels.

Squibb
AI Engineer
Trusted Enterprise Deployment
Caspia’s AI Business Agents operate on secure cloud infrastructure with role-based access, ensuring compliance with enterprise-grade data protection standards.

Sam
Statistician
Adaptive Response Framework
Inbound and Outbound AI Agents adjust their conversational flow dynamically using live metrics such as sentiment, response time, and customer satisfaction scores.

Larry
Mathematician
Real-Time Analytics Feedback
Every call and chat session generates structured analytics that can be fed back into dashboards, allowing executives to monitor engagement and performance continuously.

Tabs
Data Engineer
The Future of Business Interaction
AI Business Agents represent a shift from digital tools to autonomous enterprise assistants capable of thinking, learning, and communicating across every channel.

Mitchell
AI Researcher
Frequently Asked Questions
What exactly is an AI Business Agent?
An AI Business Agent is a virtual employee that can talk, write and act like a human. It handles calls, chats, bookings and customer support 24/7 in your brand voice. Each agent is trained on your data, workflows and tone to deliver accurate, consistent, and human-quality interactions.
How are AI Business Agents trained for my business?
We train each agent using your documentation, product data, call transcripts and FAQs. The agent learns to recognise customer intent, follow your processes, and escalate to human staff when required. Continuous retraining keeps performance accurate and up to date.
What makes AI Business Agents better than chatbots?
Unlike traditional chatbots, AI Business Agents use advanced language models, voice technology and contextual memory. They understand full conversations, manage complex requests, and speak naturally — creating a human experience without waiting times or errors.
Can AI Business Agents integrate with our existing tools?
Yes. We connect agents to your telephony, CRM, booking system and internal databases. Platforms like Twilio, WhatsApp, HubSpot, Salesforce and Google Workspace work seamlessly, allowing agents to perform real actions such as scheduling, updating records or sending follow-up emails.
How do you monitor and maintain AI Business Agents?
Our team provides 24/7 monitoring, quality checks and live performance dashboards. We retrain agents with new data, improve tone and accuracy, and ensure uptime across all communication channels. You always have full visibility and control.
What industries can benefit from AI Business Agents?
AI Business Agents are already used in healthcare, beauty, retail, professional services, hospitality and education. They manage appointments, take orders, answer enquiries, and follow up with customers automatically — freeing staff for higher-value work.
How secure is our data when using AI Business Agents?
We apply strict data governance including encryption, access control and GDPR compliance. Each deployment runs in secure cloud environments with audit logs and permission-based data access to protect customer information.
Do you still offer data and analytics services?
Yes. Data remains the foundation of every AI Business Agent. We design strategies, pipelines and dashboards in Power BI, Tableau and Looker to measure performance and reveal new opportunities. Clean, structured data makes AI agents more intelligent and effective.
What ongoing support do you provide?
Every client receives continuous optimisation, analytics reviews and strategy sessions. We track performance, monitor response quality and introduce updates as your business evolves — ensuring your AI Business Agents stay aligned with your goals.
Can you help us combine AI with our existing team?
Absolutely. Our approach is hybrid: AI agents handle repetitive, time-sensitive tasks, while your human staff focus on relationship-building and creative work. Together they create a seamless, scalable customer experience.
